 카톡상담
카톡상담Seven Reasons You should Stop Stressing About Deepseek
페이지 정보
작성자 Jerold 댓글 0건 조회 4회 작성일 25-02-22 15:54본문
You can quickly find DeepSeek by searching or filtering by mannequin suppliers. They can run on enterprise level and they have access to both hosted models and self-hosted fashions. 3. 3To be utterly precise, it was a pretrained model with the tiny quantity of RL coaching typical of models earlier than the reasoning paradigm shift. As fastened artifacts, they have turn into the article of intense study, with many researchers "probing" the extent to which they acquire and readily display linguistic abstractions, factual and commonsense knowledge, and reasoning skills. Those companies have additionally captured headlines with the huge sums they’ve invested to build ever more powerful models. However, the distillation based implementations are promising in that organisations are able to create environment friendly, smaller and accurate fashions using outputs from massive fashions like Gemini and OpenAI. While my very own experiments with the R1 mannequin showed a chatbot that mainly acts like different chatbots - whereas strolling you through its reasoning, which is attention-grabbing - the real worth is that it points toward a future of AI that's, at the least partially, open supply.
It proves we could make the fashions more environment friendly whereas conserving it open supply. FP8-LM: Training FP8 giant language models. Models of language educated on very large corpora have been demonstrated helpful for pure language processing. We also evaluated well-liked code fashions at completely different quantization levels to find out which are finest at Solidity (as of August 2024), and compared them to ChatGPT and Claude. Yes, it’s extra value efficient, however it’s also designed to excel in different areas in comparison with ChatGPT. It’s the identical factor once you attempt examples for eg pytorch. That finding explains how DeepSeek could have less computing energy but attain the identical or higher result just by shutting off an increasing number of parts of the network. DeepSeek r1 did this in a method that allowed it to make use of much less computing power. Australia has banned its use on authorities gadgets and techniques, citing nationwide safety concerns. This progressive method not only broadens the variety of coaching materials but in addition tackles privateness issues by minimizing the reliance on actual-world knowledge, which can often embody sensitive information. By delivering more correct results quicker than conventional methods, groups can concentrate on analysis slightly than trying to find data.
Furthermore, its collaborative features allow groups to share insights simply, fostering a culture of knowledge sharing within organizations. Furthermore, we enhance models’ performance on the contrast sets by making use of LIT to augment the coaching knowledge, without affecting efficiency on the original knowledge. Experimenting with our method on SNLI and MNLI exhibits that current pretrained language fashions, though being claimed to include adequate linguistic information, battle on our mechanically generated contrast units. The unique research purpose with the current crop of LLMs / generative AI based mostly on Transformers and GAN architectures was to see how we can remedy the problem of context and a spotlight missing in the earlier deep learning and neural network architectures. GPT-three didn’t assist lengthy context windows, but when for the moment we assume it did, then every further token generated at a 100K context length would require 470 GB of reminiscence reads, or round 140 ms of H100 time given the H100’s HBM bandwidth of 3.Three TB/s. The implementation was designed to help a number of numeric types like i32 and u64.
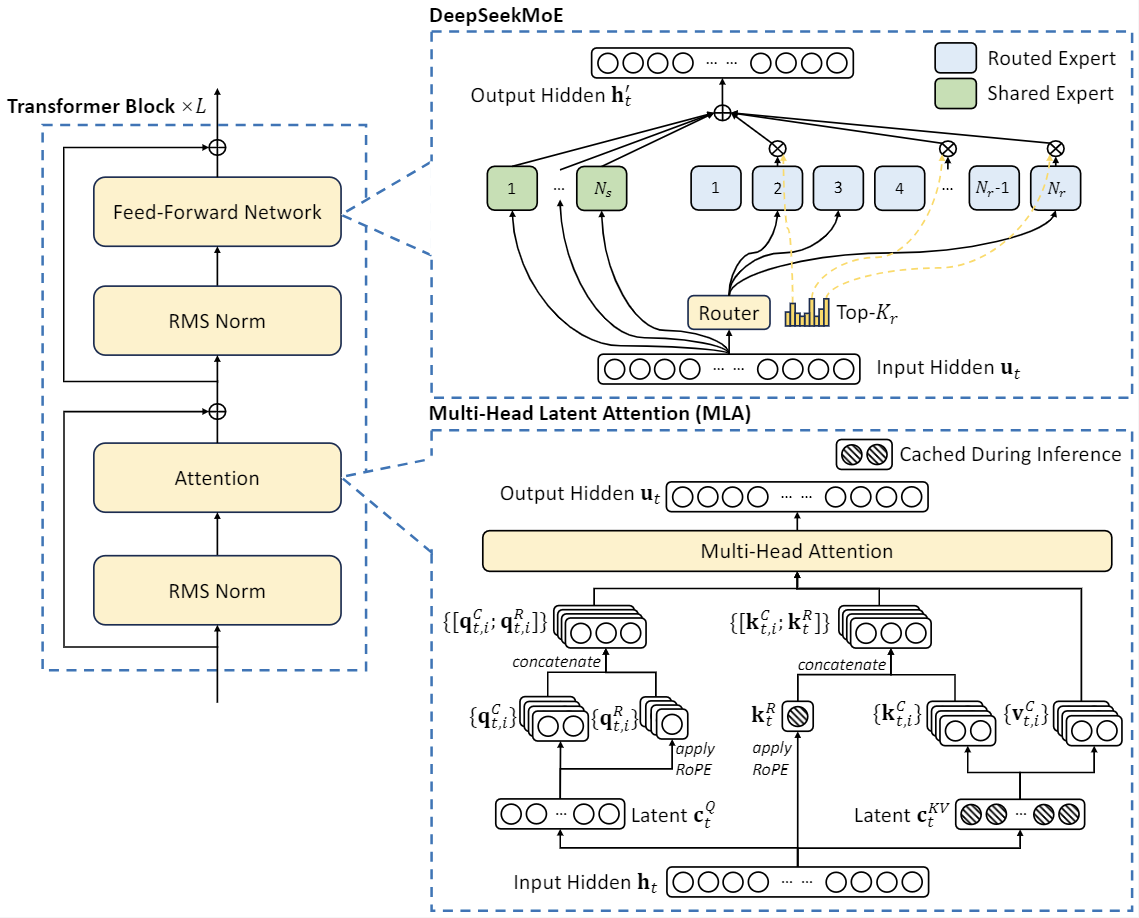 However, while these fashions are useful, especially for prototyping, we’d still like to warning Solidity builders from being too reliant on AI assistants. Unfortunately, these instruments are often dangerous at Solidity. It takes more time and effort to know however now after AI, everyone seems to be a developer because these AI-driven instruments just take command and full our wants. Get started with the Instructor using the following command. Put one other manner, whatever your computing power, you possibly can increasingly turn off components of the neural net and get the identical or higher outcomes. Graphs show that for a given neural internet, on a given amount of computing funds, there's an optimum amount of the neural net that can be turned off to succeed in a stage of accuracy. Abnar and staff ask whether or not there's an "optimum" degree for sparsity in DeepSeek and similar models, which means, for a given quantity of computing energy, is there an optimal number of those neural weights to turn on or off? In the paper, titled "Parameters vs FLOPs: Scaling Laws for Optimal Sparsity for Mixture-of-Experts Language Models," posted on the arXiv pre-print server, lead creator Samir Abnar of Apple and different Apple researchers, along with collaborator Harshay Shah of MIT, studied how performance assorted as they exploited sparsity by turning off components of the neural web.
However, while these fashions are useful, especially for prototyping, we’d still like to warning Solidity builders from being too reliant on AI assistants. Unfortunately, these instruments are often dangerous at Solidity. It takes more time and effort to know however now after AI, everyone seems to be a developer because these AI-driven instruments just take command and full our wants. Get started with the Instructor using the following command. Put one other manner, whatever your computing power, you possibly can increasingly turn off components of the neural net and get the identical or higher outcomes. Graphs show that for a given neural internet, on a given amount of computing funds, there's an optimum amount of the neural net that can be turned off to succeed in a stage of accuracy. Abnar and staff ask whether or not there's an "optimum" degree for sparsity in DeepSeek and similar models, which means, for a given quantity of computing energy, is there an optimal number of those neural weights to turn on or off? In the paper, titled "Parameters vs FLOPs: Scaling Laws for Optimal Sparsity for Mixture-of-Experts Language Models," posted on the arXiv pre-print server, lead creator Samir Abnar of Apple and different Apple researchers, along with collaborator Harshay Shah of MIT, studied how performance assorted as they exploited sparsity by turning off components of the neural web.
- 이전글입북동 누수탐지 수원 업체 완벽한 시공으로 25.02.22
- 다음글Take Heed to Your Customers. They'll Let you Know All About Vape Shop 25.02.22
댓글목록
등록된 댓글이 없습니다.